 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMuChator: Enabling Active Music Discovery via Conversational Music LLMs in Douyin Music
May 26, 2026Douyin Music, a large-scale platform with millions of daily users, adopts an immersive, feed-based discovery paradigm, where users passively explore music through continuous recommendations. While effective for passive music discovery, this paradigm restricts users to recommendation results and provides limited support for explicitly specifying listening intents. Unlike conventional search, where users express well-defined intents through explicit queries such as specific songs or artists, real-world active music discovery is often situational and colloquial, involving vague or underspecified requests. While LLMs enable natural language interaction, their direct use in music discovery remains limited by insufficient music-domain knowledge, lack of music-query collaborative reasoning, and shallow understanding of personalized preferences. To address these challenges, we introduce MuChator, an interactive MusicLLM-based framework that enables users to actively express situational music intents in natural language. MuChator incorporates three key components: (1) Music Knowledge Pre-training, a three-stage scheme that incrementally injects objective music knowledge, subjective music knowledge, and personalized music preferences into LLMs; (2) Context-aware Instruction Tuning, which constructs high-quality user-query-music triplets through an automated synthesis pipeline to align LLMs with active and situational user intents; and (3) Preference Alignment with Hybrid RM, which jointly models intent relevance, personalized preferences, and basic constraints, and is optimized using GRPO-based reinforcement learning. Extensive evaluations on industrial music recommendation datasets demonstrate that MuChator outperforms leading proprietary models, such as Gemini-3-Pro. The model has been deployed on Douyin Music App within ByteDance, with 46.49\% improvement of user active days in online A/B test.
SciAgent: A Unified Multi-Agent System for Generalistic Scientific Reasoning
Nov 17, 2025Recent advances in large language models have enabled AI systems to achieve expert-level performance on domain-specific scientific tasks, yet these systems remain narrow and handcrafted. We introduce SciAgent, a unified multi-agent system designed for generalistic scientific reasoning-the ability to adapt reasoning strategies across disciplines and difficulty levels. SciAgent organizes problem solving as a hierarchical process: a Coordinator Agent interprets each problem's domain and complexity, dynamically orchestrating specialized Worker Systems, each composed of interacting reasoning Sub-agents for symbolic deduction, conceptual modeling, numerical computation, and verification. These agents collaboratively assemble and refine reasoning pipelines tailored to each task. Across mathematics and physics Olympiads (IMO, IMC, IPhO, CPhO), SciAgent consistently attains or surpasses human gold-medalist performance, demonstrating both domain generality and reasoning adaptability. Additionally, SciAgent has been tested on the International Chemistry Olympiad (IChO) and selected problems from the Humanity's Last Exam (HLE) benchmark, further confirming the system's ability to generalize across diverse scientific domains. This work establishes SciAgent as a concrete step toward generalistic scientific intelligence-AI systems capable of coherent, cross-disciplinary reasoning at expert levels.
MorphoBench: A Benchmark with Difficulty Adaptive to Model Reasoning
Oct 16, 2025

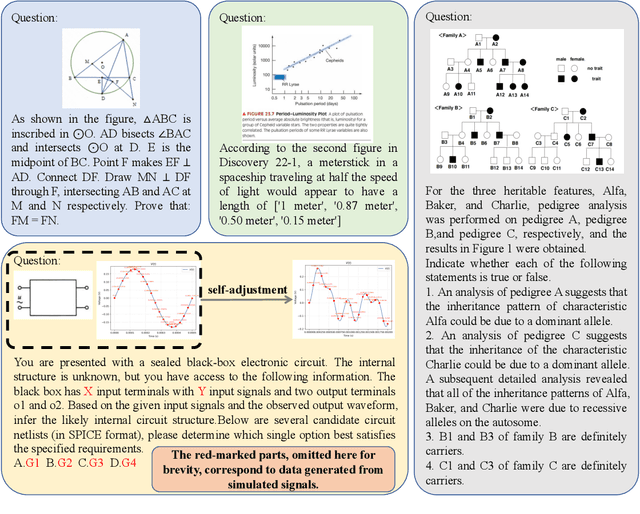
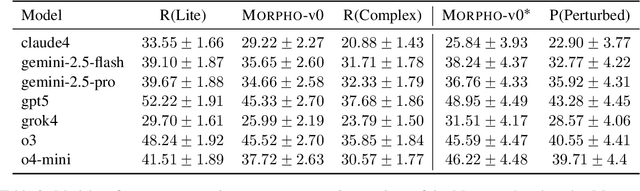
With the advancement of powerful large-scale reasoning models, effectively evaluating the reasoning capabilities of these models has become increasingly important. However, existing benchmarks designed to assess the reasoning abilities of large models tend to be limited in scope and lack the flexibility to adapt their difficulty according to the evolving reasoning capacities of the models. To address this, we propose MorphoBench, a benchmark that incorporates multidisciplinary questions to evaluate the reasoning capabilities of large models and can adjust and update question difficulty based on the reasoning abilities of advanced models. Specifically, we curate the benchmark by selecting and collecting complex reasoning questions from existing benchmarks and sources such as Olympiad-level competitions. Additionally, MorphoBench adaptively modifies the analytical challenge of questions by leveraging key statements generated during the model's reasoning process. Furthermore, it includes questions generated using simulation software, enabling dynamic adjustment of benchmark difficulty with minimal resource consumption. We have gathered over 1,300 test questions and iteratively adjusted the difficulty of MorphoBench based on the reasoning capabilities of models such as o3 and GPT-5. MorphoBench enhances the comprehensiveness and validity of model reasoning evaluation, providing reliable guidance for improving both the reasoning abilities and scientific robustness of large models. The code has been released in https://github.com/OpenDCAI/MorphoBench.
A Comprehensive Survey on Continual Learning in Generative Models
Jun 16, 2025The rapid advancement of generative models has enabled modern AI systems to comprehend and produce highly sophisticated content, even achieving human-level performance in specific domains. However, these models remain fundamentally constrained by catastrophic forgetting - a persistent challenge where adapting to new tasks typically leads to significant degradation in performance on previously learned tasks. To address this practical limitation, numerous approaches have been proposed to enhance the adaptability and scalability of generative models in real-world applications. In this work, we present a comprehensive survey of continual learning methods for mainstream generative models, including large language models, multimodal large language models, vision language action models, and diffusion models. Drawing inspiration from the memory mechanisms of the human brain, we systematically categorize these approaches into three paradigms: architecture-based, regularization-based, and replay-based methods, while elucidating their underlying methodologies and motivations. We further analyze continual learning setups for different generative models, including training objectives, benchmarks, and core backbones, offering deeper insights into the field. The project page of this paper is available at https://github.com/Ghy0501/Awesome-Continual-Learning-in-Generative-Models.